이번에는 피처스케일링과 그 방법 중 가장 많이 쓰이는 min-max 정규화와 표준화에 대해 정리해보았습니다.
피처 스케일링
- 서로 다른 피처 값의 범위(최댓값 - 최솟값)가 일치하도록 조정하는 작업
- 값의 범위가 데이터마다 다르면 모델 훈련이 제대로 안 될수도 있다
서로 다른 피처값의 범위란 어떤 의미인지 키(m)와 몸무게(kg)로 예를 들 수 있다.
| 이름 | 키(m) | 몸무게(kg) | 옷 사이즈 |
| 광일 | 1.7 | 75 | L |
| 혜성 | 1,5 | 55 | S |
| 덕수 | 1.8 | 60 | ? |
이 데이터에서 덕수의 옷 사이즈를 예측한다고 하자.
키와 몸무게를 더하는 방법을 사용할 수 있다.
- 광일: 1.7 + 75 = 76.7
- 혜성: 1.5 + 55 = 56.5
- 덕수: 1.8 + 60 = 61.8
덕수의 키와 몸무게 합은 혜성에 더 가깝기 때문에 머신러닝 모델은 덕수의 옷 사이즈를 S로 예측할 것이다.
하지만 실제로 덕수는 키가 크므로 L 사이즈가 더 적합할 것이다.
이렇게 두 특성(키와 몸무게)의 값이 놓인 범위가 매우 다를때, 두 특성의 스케일이 다르다고도 한다.
알고리즘이 거리 기반일 때 제대로 사용하려면 특성값을 일정한 기준으로 맞춰 주어야 한다.
그 방법 중 min-max 정규화와 표준화에 대해 알아보자.
1. min-max 정규화
- 피처 값의 범위를 0~1로 조정하는 기법
- 조정 후 최솟값은 0, 최댓값은 1
- 피처 x에서 최솟값을 뺀 뒤 그 값을 최댓값과 최솟값의 차이로 나눈다
- 사이킷런의 MinMaxScaler로 구현 가능
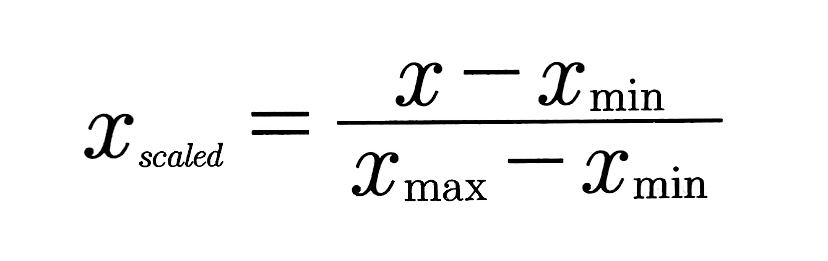
min-max 정규화를 옷 사이즈 예측에 적용하면 다음과 같다.
| 이름 | min-max 정규화한 키 | min-max 정규화한 몸무게 | 키 + 몸무게 |
| 광일 | (1.7 - 1.5) / (1.8 - 1.5) = 0.67 | (75 - 55) / (75 - 55) = 1 | 1.67 |
| 혜성 | (1.5 - 1.5) / (1.8 - 1.5) = 0 | (55 - 55) / (75 - 55) = 0 | 0 |
| 덕수 | (1.8 - 1.5) / (1.8 - 1.5) = 1 | (60 - 55) / (75 - 55) = 0.25 | 1.25 |
min-max 정규화한 후 덕수의 키와 몸무게 합은 1.25가 되어 광일에 더 가까워졌다.
이렇게 피처 스케일링을 적용하여 덕수의 옷 사이즈를 L이라고 예측할 수 있게 되었다.
이제 min-max 정규화를 사이킷런의 MinMaxScaler로 구현해보자.
먼저 원본 데이터를 만든다.
import pandas as pd
height_weight_dict = {'키': [1.7, 1.5, 1.8], '몸무게': [75, 55, 60]}
df = pd.DataFrame(height_weight_dict, index=['광일', '혜성', '덕수'])
print(df)
키 몸무게
광일 1.7 75
혜성 1.5 55
덕수 1.8 60
MinMaxScaler 객체를 생성해서 피처 스케일링을 적용한다.
from sklearn.preprocessing import MinMaxScaler
# min-max 정규화 객체 생성
scaler = MinMaxScaler()
# min-max 정규화 적용
scaler.fit(df)
df_scaled = scaler.transform(df)
print(df_scaled)
[[0.66666667 1. ]
[0. 0. ]
[1. 0.25 ]]
2. 표준화(standardization)
- 평균이 0, 분산이 1이 되도록 피처 값을 조정하는 기법
- min-max 정규화와 다르게 상한과 하한이 없다(min-max 적용 시 상한 1, 하한 0)
- 상한, 하한을 정하는 경우가 아니라면 표준화 적용 가능
- 사이킷런의 StandardScaler로 구현 가능

표준화의 공식은 우리가 많이 보았던 정규분포 표준화 공식과 같다.
위의 키와 몸무게 데이터를 그대로 사용하여
사이킷런의 StandardScaler로 표준화를 구현해보자.
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
scaler = StandardScaler()
# 표준화 적용
df_scaled = scaler.fit_transform(df)
print(df_scaled)
[[ 0.26726124 1.37281295]
[-1.33630621 -0.98058068]
[ 1.06904497 -0.39223227]]
정규분포를 따르는 데이터는 표준화 스케일링을 적용하는 것이 좋다.
그리고 이상치(대부분의 값과 동떨어진 값)가 너무 크거나 작을 때는 min-max 정규화가 좋지 않은 결과를 낼 수 있으므로
이상치가 너무 크거나 작을 때는 평균을 0, 분산이 1이 되도록 조정해주는 표준화가 더 바람직하다.
참고 교재

머신러닝·딥러닝 문제해결 전략 | 신백균
[머신러닝·딥러닝 문제해결 전략 - chapter5]
'ML,DL' 카테고리의 다른 글
| [머신러닝/딥러닝] 향후 판매량 예측 경진대회: 분석정리 및 시각화 (0) | 2022.11.19 |
|---|---|
| [머신러닝/딥러닝] 안전 운전자 예측 경진대회: 분석정리 및 시각화 (0) | 2022.11.07 |
| [머신러닝/딥러닝] 범주형 데이터 이진분류 경진대회: 분석정리 및 시각화 (1) | 2022.10.04 |
| [머신러닝/딥러닝] 데이터 인코딩(레이블, 원-핫) (1) | 2022.09.19 |
| [머신러닝/딥러닝] 분류와 회귀, 평가지표 (0) | 2022.09.18 |



