범주형 데이터를 활용해 이진부류를 하는 경진대회 문제를 풀어보았다.
다양한 범주형 데이터를 활용해 타깃값 1에 속할 확률을 예측하는 것이 목표이다.
<대회 정보와 데이터>
Categorical Feature Encoding Challenge
https://www.kaggle.com/competitions/cat-in-the-dat/overview
Categorical Feature Encoding Challenge | Kaggle
www.kaggle.com
<참고 코드>
https://www.kaggle.com/code/kabure/eda-feat-engineering-encode-conquer/notebook
EDA & Feat Engineering - Encode & Conquer
Explore and run machine learning code with Kaggle Notebooks | Using data from Categorical Feature Encoding Challenge
www.kaggle.com
데이터 둘러보기
데이터가 어떻게 구성되어있는지 살펴보도록 하자.
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col = 'id')
test = pd.read_csv(data_path + 'test.csv', index_col = 'id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col = 'id')
▶ index_col: 불러올 DataFrame의 인덱스 지정. 인덱스로 지정할 칼럼명을 입력하면 된다.
명시하지 않을 시 오른쪽처럼 0부터 시작하는 새로운 인덱스 열을 생성한다.

id는 타깃값을 예측하는 데 정보를 제공하지 않고 행을 구분하는 역할만 하므로 인덱스로 지정했다.
# 훈련 데이터와 테스트 데이터 크기 확인
train.shape, test.shape

훈련 데이터는 300000행 24열, 테스트 데이터는 200000행 23열로 구성되어있는 것을 확인했다.
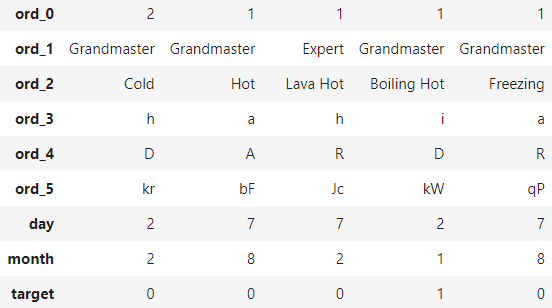
train.head().T
훈련데이터가 어떻게 이루어져있는지 살펴보기 위해 head()를 사용했다.
이 데이터는 피처 개수가 많기 때문에 옆으로 길어 보기 불편하다.
T 메서드를 호출하면 행과 열의 위치를 바꿔주어 한눈에 보기 편해진다.
이 메서드는 아래 코드를 사용하여 같은 결과를 낼 수도 있다.
train.head().transpose()

# 제출 샘플 데이터 출력
submission.head()

피처 요약표 만들기
이제 피처 요약표를 만들어 각 피처를 살펴볼 것이다.
피처 요약표는 피처별 데이터 타입, 결측값 개수, 고윳값 개수, 실제 입력값을 정리한 표다.
def resumetable(df):
print(f'데이터 세트 형상: {df.shape}')
summary = pd.DataFrame(df.dtypes, columns=['데이터 타입'])
summary = summary.reset_index() # 새로운 인덱스
summary = summary.rename(columns={'index': '피처'}) # 열 이름 변경
summary['결측값 개수'] = df.isnull().sum().values # 피처별 결측값 개수
summary['고윳값 개수'] = df.nunique().values # 피처별 고윳값 개수
summary['첫 번째 값'] = df.loc[0].values # 피처별 첫 행 입력값
summary['두 번째 값'] = df.loc[1].values
summary['세 번째 값'] = df.loc[2].values
return summary
resumetable(train)
<피처 요약표 만드는 과정>
- 피처별 데이터 타입 DataFrame 생성
- 인덱스 재설정 후 열 이름 변경: reset_index()로 피처 이름으로 된 현재 인덱스를 열로 옮기고 열 이름 재설정.
- 결측값 개수, 고윳값 개수, 1~3행 입력값 추가
- 피처 요약표 해석
위에서 24개의 피처가 있는 것을 확인했었다. 내용이 많으므로 네 부류로 묶어볼 수 있다.
1. 이진(binary) 피처: bin_0 ~ bin_4
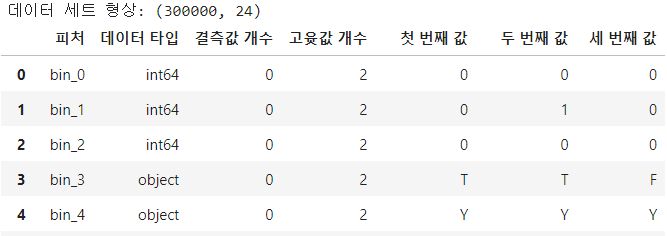
bin_0 ~ bin_4는 모두 고윳값 개수가 2개로 이진피처다.
0/1, T/F, Y/N로 구성되어있는데 이 중 숫자가 아닌 구성값들은 모두 1과 0으로 인코딩하여 모델링해야한다.
머신러닝 모델은 숫자만 인식하기 때문이다.
2. 명목형(nominal)피처: nom_0 ~ nom_9

명목형 피처의 데이터 타입은 모두 object이고 결측값은 없다.
nom_5부터는 고윳값이 많으며 의미를 알 수 없는 값들이 입력되어 있다.
3. 순서형(ordinal) 피처: ord_0 ~ ord_5
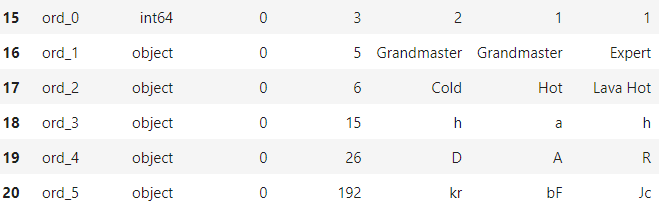
명목형 데이터와 다르게 순서형 데이터는 순서가 중요하다.
순서에 따라 타깃값에 미치는 영향이 다르기 때문이다. 순서에 유의하여 인코딩하도록 하자.
순서를 파악하기 위해 순서형 피처의 고윳값을 출력해보겠다.
먼저, 고윳값이 적은 ord_0 ~ ord_2 피처부터 출력해보자.
# 순서형 피처 고윳값 구하기
for i in range(3) :
feature = 'ord_' + str(i)
print(f'{feature} 고윳값: {train[feature].unique()}')

unique() 함수를 이용해서 고윳값이 등장한 순으로 어떤 값이 있는지 볼 수 있다.
- ord_0: 캐글 등급 -> 숫자 크기에 맞춤
- ord_1: 등급 단계 -> 등급 단계에 따라 맞춤 (Novice ~ Grandmaster)
- ord_2: 춥고 더운 정도 -> 온도에 따라 맞춤 (Freezing ~ Lava)
다음으로 고윳값이 많은 ord_3 ~ ord_5 피처의 고윳값을 출력해보았다.

ord_3 ~ ord_5 -> 알파벳순으로 인코딩
4. 그 외 피처: day, month, target

일, 월 타깃값 피처 모두 int64 타입이다. 각 고윳값은 어떤 것이 있을지 보겠다.
print('day 고윳값:', train['day'].unique())
print('month 고윳값:', train['month'].unique())
print('target 고윳값:', train['target'].unique())

- day: 고윳값이 7개므로 요일을 나타낼 것으로 예상할 수 있음
- month: 고윳값이 1~12로 월을 나타냄
- target: 0 또는 1로 구성되어있음
여기까지 피처에 대해 살펴보았다. 다음은 데이터 시각화를 통해 타깃값 별 피처 분포를 알아보겠다.
시각화를 통해 어떤 피처가 중요한지, 어떤 고윳값이 타깃값에 영향을 많이 주는지 알 수 있게 된다.
데이터 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
타깃값 분포
첫 번째로 타깃값 분포에 대해 알아본다.
타깃값 분포를 통해 데이터가 얼마나 불균형한지 파악하고, 부족한 타깃값에 더 집중해 모델링 할 수 있다.
카운트 플롯(count plot)으로 타깃값 0과 1 개수를 파악해볼 것이다. (보통 양성:1이 음성:0에 비해 개수가 적다.)
카운트 플롯은 범주형 데이터 개수를 확인할 때 주로 사용한다.
* displot(): 수치형 데이터 분포 / countplot(): 범주형 데이터 분포
mpl.rc('font', size = 15) # 폰트 크기 설정
plt.figure(figsize = (7,6)) # Figure 크기 설정
# 타깃값 분포 카운트플롯
ax = sns.countplot(x = 'target', data = train)
ax.set_title('Target Distribution')

train['target']에서 고윳값 별로 데이터가 몇 개인지 보여주는 카운트 플롯이다.
타깃값 0은 20만 개가 조금 넘고, 타깃값 1은 약 9만 개 정도 있다.
이 플롯에 각 값의 비율을 상단에 표시하면 더 좋을 것 같다.
먼저 비율을 표시할 위치를 구해야 한다.
위치를 구하기 위해서 사각형의 높이, 너비, 왼쪽 테두리의 축 위치 정보가 필요하다.
rectangle = ax.patches[0] # 첫 번째 Rectangle 객체
print('사각형 높이: ', rectangle.get_height())
print('사각형 너비: ', rectangle.get_width())
print('사각형 왼쪽 테두리의 x축 위치: ', rectangle.get_x())

- patches: matplotlib.patches 모듈은 그래프에 다양한 2D 도형을 표현하기 위한 클래스를 담고 있다.
- ax.patches: ax축을 구성하는 그래프 도형 객체를 모두 담은 리스트
- get.height(): 객체 도형의 높이
- get.width(): 객체 도형의 너비
- get_x(): 왼쪽 테두리 x축 위치 반환
위 코드로 위치를 구하는 방법을 알았다. 이 값들을 이용해서 막대 바로 가운데 위에 표시할 것이다.
print('텍스트 위치의 x좌표:', rectangle.get_x() + rectangle.get_width()/2.0)
print('텍스트 위치의 y좌표:', rectangle.get_height() + len(train)*0.001)
막대 가운데 위에 표시하기 위해
텍스트의 x좌표는 왼쪽 테두리 x축 위치에서 도형 너비의 반만큼 이동한 값을 더하고,
텍스트의 y좌표는 도형의 높이 위치에서 막대 도형의 높이 위 값을 더해주었다.
* countplot()에서 막대 도형의 높이는 데이터 개수와 같다.
이렇게 위치를 구했다.
이제 비율을 표시해주는 코드를 함수로 구현한 다음 함수를 사용해서 카운트 플롯을 그리면 된다.
def write_percent(ax, total_size):
'''도형 객체를 순회하며 막대 상단에 타깃값 비율 표시'''
for patch in ax.patches:
height = patch.get_height() # 도형 높이(데이터 개수)
width = patch.get_width() # 도형 너비
left_coord = patch.get_x() # 도형 왼쪽 테두리의 x축 위치
percent = height/total_size*100 # 타깃값 비율
# (x, y) 좌표에 텍스트 입력
ax.text(x=left_coord + width/2.0, # x축 위치
y=height + total_size*0.001, # y축 위치
s=f'{percent:1.1f}%', # 입력 텍스트
ha='center') # 가운데 정렬
plt.figure(figsize=(7, 6))
ax = sns.countplot(x='target', data=train)
write_percent(ax, len(train)) # 비율 표시
ax.set_title('Target Distribution');

각 막대 가운데 위에 비율이 표시되었다. 비율이 표시되어 의미를 파악하기 더 쉬워졌다.
타깃값이 약 7대 3 비율로 구성되어있다.
이진 피처 분포
이진 피처의 분포를 타깃값별로 그려볼 것이다.
범주형 피처 타깃값 분포를 고윳값별로 구분해 그리는 것은 분류 문제에서 종종 쓰인다.
이를 통해 특정 고윳값이 특정 타깃값에 치우치는지 확인할 수 있다.
import matplotlib.gridspec as gridspec # 여러 그래프를 격자 형태로 배치
# 3행 2열 틀(Figure) 준비
mpl.rc('font', size = 12)
grid = gridspec.GridSpec(3,2) # 그래프(서브플롯)를 3행 2열로 배치
plt.figure(figsize = (10,16)) # 전체 Figure 크기 설정
plt.subplots_adjust(wspace = 0.4, hspace = 0.3) # 서브플롯 간 좌우/상하 여백 설정
# 서브플롯 그리기
bin_features = ['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4'] # 피처 목록
for idx, feature in enumerate(bin_features) :
ax = plt.subplot(grid[idx])
# ax축에 타깃값 분포 카운트플롯 그리기
sns.countplot(x = feature,
data = train,
hue = 'target',
palette = 'pastel',
ax = ax)
ax.set_title(f'{feature} Distribution by Target') # 그래프 제목 설정
write_percent(ax, len(train)) # 비율표시
<countplot()에 전달된 파라미터>
- x: 피처
- data: 전체 데이터셋
- palette:그래프 색상맵
- ax: 그래프를 그릴 축
이 코드에서 enumerate 함수가 궁금해서 알아보았다.
- enumerate(): 인덱스를 추가하여 입력받은 데이터와 함께 리턴
무슨 말인지 코드와 결과값으로 확인해보자.
bin_features = ['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4']
for idx, feature in enumerate(bin_features) :
print(idx, feature)

enumerate가 인덱스값을 부여해준 것을 확인할 수 있었다.
이렇게 인덱스값을 반환해주어 idx에 인덱스값이, feature에 피처값을 한 번에 넣을 수 있다.
이진피처 분포도 코드를 실행한 결과 다음과 같다.

고윳값 별 타깃값의 분포는 대체로 7:3 수준인 것을 확인했다.
이진 피처들이 특정 타깃값에 치우치지 않았음을 알 수 있다.
명목형 피처 분포
위에서 명목형 피처를 보았을 때 nom_5 ~ nom_9는 고윳값 개수가 많고,
의미를 알 수 없는 문자열이 포함되어있었으므로 nom_0 ~ nom_4 피처까지 시각화해보겠다.
<명목형 피처 분포 시각화 순서>
- 교차분석표 생성 함수 만들기
- 포인트플롯 생성 함수 만들기
- 피처 분포도 및 포인트플롯 생성 함수 만들기
결과 그래프를 먼저 보도록 하자.

이 그래프에서 카운트플롯은 각 고윳값의 비율을 나타낸다.
꺾은 선 그래프는 포인트플롯으로, 해당 고윳값의 타깃값이 1인 비율을 나타낸다.
다섯 피처에서 고윳값별로 타깃값 1 비율이 서로 다르므로 타깃값에 대한 예측 능력이 있다고 볼 수 있다.
1. 교차분석표 생성 함수 만들기
교차표(교차분석표): 각 범주형 데이터의 빈도나 통계량을 행과 열로 결합한 표. 범주형 데이터 2개를 비교 분석하는 데 사용됨
교차분석표가 필요한 이유는 명목형 피처별 타깃값 1 비율을 구하기 위해서다.
판다스의 crosstab() 함수로 교차분석표를 만들 수 있다.
다음은 명목형 피처인 nom_0과 타깃값 간의 교차 분석표를 만드는 코드다.
pd.crosstab(train['nom_0'], [train['target']])

nom_0의 각 고윳값별 타깃값 0과 1이 몇 개 있는지 볼 수 있다.
이를 비율로 표현하면 더 보기 좋을 것이다. normalize 파라미터를 추가하면 가능하다.
normalize 파라미터에 'index'를 전달하면 인덱스 기준으로 정규화한다.
# 정규화 후 비율을 백분율로 표현
crosstab = pd.crosstab(train['nom_0'], train['target'], normalize = 'index') * 100
crosstab

이 분석표에서 인덱스는 nom_0이므로 각 행별로, 즉 고윳값별로 비율을 정규화한다.
* 열을 기준으로 정규화하려면 normalize = 'columns'
정규화한 값은 비율이므로 백분율로 표현하기 위해서 100을 곱했다.
다음은 인덱스를 재설정한다. 현재 인덱스는 nom_0으로 피처이름이다.
이를 열로 가져와야 그래프를 그릴 때 쉽다.
# 인덱스 재설정
crosstab = crosstab.reset_index()
crosstab

위에서 사용한 것처럼 reset_index()를 이용하면 쉽게 인덱스를 재설정 할 수 있다.
교차분석표는 앞으로 자주 사용할 것이다.
쉽게 재사용하기 위해서 함수로 만드는 것이 좋다.
# 교차분석표 함수로 만들기
def get_crosstab(df, feature):
crosstab = pd.crosstab(df[feature], df['target'], normalize = 'index') * 100
crosstab = crosstab.reset_index()
return crosstab
이 함수로 위의 교차분석표와 같은 결과를 낼 수 있다.
crosstab = get_crosstab(train, 'nom_0')
crosstab

2. 포인트플롯 생성 함수 만들기
1에서 구한 교차분석표를 사용해 타깃값 1의 비율을 나타내는 포인트플롯을 그리는 함수를 만든다.
# plot_pointplot(): 이미 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그림
def plot_pointplot(ax, feature, crosstab):
ax2 = ax.twinx() # twinx: x축은 공유하고 y축은 공유하지 않는 새로운 축 생성
# 새로운 축에 포인트플롯 그리기
ax2 = sns.pointplot(x = feature, y=1, data = crosstab,
order = crosstab[feature].values, # 포인트플롯 순서
color = 'black',
legend = False)
ax2.set_ylim(crosstab[1].min() - 5, crosstab[1].max() * 1.1) # y축 범위 설정
ax2.set_ylabel('Target 1 Ratio(%)')
- ax: 포인트플롯을 그릴 축
- feature: 포인트 플롯으로 그릴 피처
- crosstab: 교차분석표
plot_pointplot()은 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그려준다.
twinx()는 x축만 공유하고 y축은 따로 쓸 수 있게하는 함수다.
ax2는 포인트플롯을 그리기 위한 축이다. ax와 ax2는 x축을 공유하지만, y축은 서로 다르다.
3. 피처 분포도 및 피처별 타깃값 1의 비율 포인트플롯 생성 함수 만들기
1과 2에서 만든 get_crosstab()과 plot_pointplot() 함수를 사용해서 최종적인 그래프를 그린다.
def plot_cat_dist_with_true_ratio(df, features, num_rows, num_cols,
size = (15, 20)):
plt.figure(figsize = size) # 전체 Figure 크기 설정
grid = gridspec.GridSpec(num_rows, num_cols) # 서브플롯 배치
plt.subplots_adjust(wspace=0.45, hspace=0.3) # 서브플롯 좌우/상하 여백 설정
for idx, feature in enumerate(features):
ax = plt.subplot(grid[idx])
crosstab = get_crosstab(df, feature) # 교차분석표 생성
# ax축에 타깃값 분포 카운트플롯 그리기
sns.countplot(x=feature, data=df,
order=crosstab[feature].values,
color='skyblue',
ax=ax)
write_percent(ax, len(df)) # 비율 표시
plot_pointplot(ax, feature, crosstab) # 포인트플롯 그리기
ax.set_title(f'{feature} Distribution') # 그래프 제목 설정
- GridSpec을 사용해 서브플롯들을 격자 형태로 배치
- for문과 enumerate로 각 피처를 순회하며 서브플롯을 그림
- 각 서브플롯에 대해 해당 피처와 타깃값의 교차 분석표 생성
- 카운트플롯 생성
- 카운트플롯에 비율 표시
- 카운트플롯과 같은 축에 포인트플롯 그리기
- 제목 추가
nom_features = ['nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4'] # 명목형 피처
plot_cat_dist_with_true_ratio(train, nom_features, num_rows=3, num_cols=2)위 코드를 실행하면 그래프가 나온다.
순서형 피처 분포
위에서 만든 plot_cat_dist_with_true_ratio() 함수로 순서형 피처 분포도를 만들 수 있다.
순서형 피처는 ord_0 ~ ord_3까지는 고윳값이 15개 이하로 적다.
반면 ord_4와 ord_5는 훨씬 많기 때문에 2행 2열 / 2행 1열로 나누어 그렸다.
먼저 ord_0 ~ ord_3의 분포를 살펴보자.
ord_features = ['ord_0', 'ord_1', 'ord_2', 'ord_3'] # 순서형 피처
plot_cat_dist_with_true_ratio(train, ord_features, num_rows = 2, num_cols = 2, size = (15, 12))

순서형 피처는 순서가 중요하다고 위에서 말했다.
ord_1과 ord_2는 등급단계와 춥고 더운 정도로, 피처 값들의 순서가 정리되지 않았다.
두 피처 값들을 순서대로 정렬해보겠다.
CategoricalDtype()을 이용하면 피처에 순서를 지정할 수 있다.
원래 범주형 데이터 타입을 만주는 함수지만 파라미터를 다음과 같이 설정하면 순서도 지정할 수 있다.
- categories: 범주형 데이터 타입으로 인코딩할 값 목록
- ordered: True로 설정하면 categories에 전달한 값의 순서가 유지된다.
from pandas.api.types import CategoricalDtype
ord_1_value = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster']
ord_2_value = ['Freezing', 'Cold', 'Warm', 'Hot', 'Booiling Hot', 'Lava Hot']
# 순서를 지정한 범주형 데이터 타입
ord_1_dtype = CategoricalDtype(categories = ord_1_value, ordered = True)
ord_2_dtype = CategoricalDtype(categories = ord_2_value, ordered = True)
# 데이터 타입 변경
train['ord_1'] = train['ord_1'].astype(ord_1_dtype)
train['ord_2'] = train['ord_2'].astype(ord_2_dtype)
plot_cat_dist_with_true_ratio(train, ord_features,
num_rows = 2, num_cols = 2, size = (15, 12))

피처 ord_1과 ord_2에 지정한 순서대로 잘 정렬되었다.
고윳값 순서에 따라 타깃값 1의 비율이 커진다는 것을 확인할 수 있다.
나머지 ord_4와 ord_5의 분포를 보자.
plot_cat_dist_with_true_ratio(train, ['ord_4', 'ord_5'],
num_rows = 2, num_cols = 1, size = (15, 12))

두 피처값은 확실히 앞의 피처보다 고윳값들이 많다. ord_5는 고윳값 개수가 많아 x축 라벨이 겹쳐져있다.
하지만 비율의 전체적인 양상을 보는 것은 가능하다. 앞의 피처들처럼 고윳값 순서에 따라 타깃값 1의 비율이 증가한다는 사실을 발견할 수 있다.
순서형 피처 모두 순서와 비율 사이에 상관관계가 있으므로 순서형 피처 중에서 필요 없는 피처는 없어 보인다.
이 피처들 모두 모델링 시 사용하도록 한다.
날짜 피처 분포
마지막으로 요일과 월 피처 분포를 살펴보자.
date_features = ['day', 'month']
plot_cat_dist_with_true_ratio(train, date_features,
num_rows = 2, num_cols = 1, size = (10, 10))
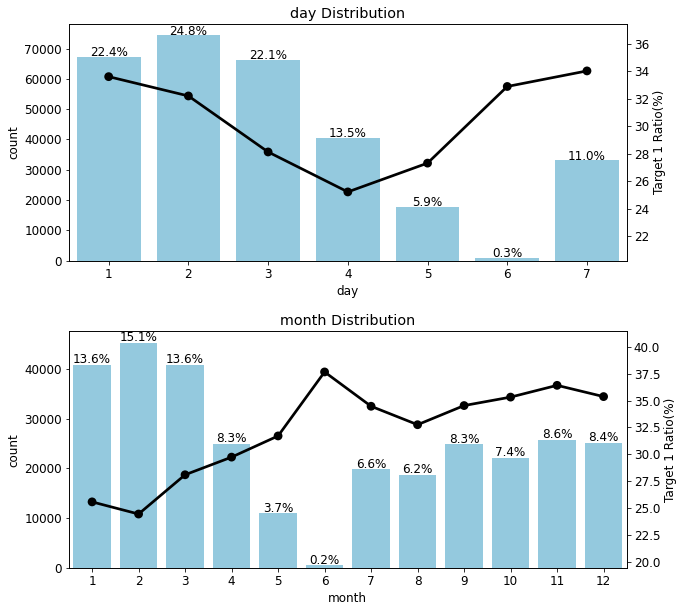
day는 피처값이 7개인 것을 보아 요일을 의미한다고 추측할 수 있다.
day와 month 피처의 타깃값 1 비율 양상은 반대로 나타난다. day가 1에서 4로 갈수록 타깃값 1 비율이 줄어들고, month는 반대로 늘어납니다.
그리고 요일과 월 피처 값 모두 숫자로 이루어져있다.
머신러닝 모델은 숫자 값을 기준으로 크고 작음을 해석한다. 이는 12월과 다음해 1월, 1월과 2월의 한 달 차이를 같다고 보지 않는다. 숫자 값을 기준으로 1월과 12월은 11이 차이가 나기 때문이다.
이런 경우 삼각함수(sin, cos)를 사용해 인코딩 하면 시작과 끝을 매끄럽게 연결할 수 있다. 하지만 데이터 크기가 크지 않기 때문에 원-핫 인코딩을 적용하도록 한다.
이처럼 매년, 매월, 매주, 매일 반복되는 데이터를 순환형 데이터(cyclical data)라고 한다. (계절, 월, 요일, 시간 등)
분석 정리 및 모델링 전략
위에서 데이터를 둘러보고 시각화 분석 결과 정리
- 결측값은 없다.
- 모든 피처가 중요하기 때문에 제거할 피처가 없다.
- 이진 피처 인코딩: 값이 숫자가 아닌 피처(bin_3 ~ bin_4)는 0과 1로 인코딩
- 순서형 피처 인코딩: 고윳값들의 순서에 맞게 인코딩한다
- 날짜 피처 인코딩: 값의 크고 작음으로 해석되지 못하도록 원-핫 인코딩 한다.
참고 교재

머신러닝·딥러닝 문제해결 전략 | 신백균
[머신러닝·딥러닝 문제해결 전략 - chapter7]
'ML,DL' 카테고리의 다른 글
| [머신러닝/딥러닝] 향후 판매량 예측 경진대회: 분석정리 및 시각화 (0) | 2022.11.19 |
|---|---|
| [머신러닝/딥러닝] 안전 운전자 예측 경진대회: 분석정리 및 시각화 (0) | 2022.11.07 |
| [머신러닝/딥러닝] 피처 스케일링: min-max 정규화, 표준화 (2) | 2022.09.19 |
| [머신러닝/딥러닝] 데이터 인코딩(레이블, 원-핫) (1) | 2022.09.19 |
| [머신러닝/딥러닝] 분류와 회귀, 평가지표 (0) | 2022.09.18 |



