
이번 9장은 과거 판매 데이터를 기반으로 향후 판매량을 예측하는 경진대회에 참가한다.
<대회 정보와 데이터>
Predict Future Sales
Predict Future Sales | Kaggle
www.kaggle.com
<참고 코드>
https://www.kaggle.com/code/dimitreoliveira/model-stacking-feature-engineering-and-eda/notebook
Model stacking, feature engineering and EDA
Explore and run machine learning code with Kaggle Notebooks | Using data from Predict Future Sales
www.kaggle.com
본 경진대회의 목표는 과거 판매 데이터(2013.01 ~ 2015.10)를 보고 향후 판매량을 예측하는 것이다.
타깃값은 판매량이므로 범주형 데이터가 아니다. 따라서 이번 대회는 회귀 문제에 속한다.
훈련데이터는 2013년 1월부터 2015년 10월까지의 일별 과거 판매 데이터가 제공된다.
상점과 상품 목록은 매월 조금씩 변경된다. 이러한 상황을 처리할 수 있는 모델을 만들어야 할 것이다.
이 데이터들을 토대로 2015년 11월 각 상점의 상품별 월간 판매량을 예측해야 한다.
지금까지 경진대회에서는 데이터 파일을 훈련 데이터, 테스트 데이터, 샘플 제출 데이터로 총 3개씩 제공했는데, 이번에는 6개를 제공한다.

데이터의 각 의미는 캐글 경진대회 페이지에서 볼 수 있다.
- item_categories.csv - 상품분류에 관한 추가 정보
- items.csv - 상품에 대한 추가 정보.
- sales_train.csv - 훈련 세트. 2013년 1월부터 2015년 10월까지의 일일 과거 데이터.
- sample_submission.csv - 샘플 제출 파일.
- shops .csv - 상점에 대한 추가 정보.
- test.csv - 테스트 세트. 2015년 11월 각 상점의 월간 판매량을 예측해야함.
주의해야할 점도 있다.

각 상점의 상품별 월간 판매량(타깃값)은 0개에서 20개 사이여야 한다. 월간 판매량이 20개보다 많으면 20개로 간주한다는 의미이다. 그러므로 타깃값뿐만 아니라 판매량과 관련된 피처는 모두 0~20으로 값을 제한해야한다.
- 유형 및 평가지표: 회귀, RMSE
데이터 둘러보기
먼저 데이터를 불러와서 추가 정보 데이터인 sales_train, shops, items, item_categories 데이터가 어떻게 구성되어 있는지 살펴보고 병합해보도록 하겠다.
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/competitive-data-science-predict-future-sales/'
sales_train = pd.read_csv(data_path + 'sales_train.csv')
shops = pd.read_csv(data_path + 'shops.csv')
items = pd.read_csv(data_path + 'items.csv')
item_categories = pd.read_csv(data_path + 'item_categories.csv')
test = pd.read_csv(data_path + 'test.csv')
submission = pd.read_csv(data_path + 'sample_submission.csv')
첫 번째로 sales_train 데이터를 출력해본다.
sales_train.head()

sales_train 데이터는
▶ date: 날짜 (일.월.연도)
▶ date_block_num: 편의상 사용하는 날짜(월) 구분자. (0 - 2013년 1월, 1 - 2013년 2월, 33 - 2015년 10월)
-> 본 경진대회 타깃값은 '월별' 판매량이므로 '월' 구분자만 있으면 된다. 따라서 date_block_num 피처만 있으면 되므로 date피처는 제거한다.
▶ shop_id, item_id: 상점ID, 상품ID
▶ item_price: 상품 판매가 (러시아 데이터라서 화폐단위 루블 - 1루블 = 약 15원)
-> 상품 판매가는 날짜나 상점에 따라 다를 수 있다. 고정된 가격이 아님
▶ item_cnt_day: 당일 판매량
-> '월간'이 아니므로 이 피처로 월간 판매량을 구해야한다. 각 상점의 상품별 일일 판매량을 월별로 합친 값이 곧 각 상점의 상품별 월간 판매량이 된다.
* date_block_num 피처를 기준으로 그룹화해서 item_cnt_day 값을 합하면 타깃값이 된다.
info() 함수로 세부사항도 살펴보았다.
sales_train.info(show_counts=True)

DataFrame 행이 1,690,785개보다 많거나 열이 100개보다 많으면 info() 함수는 비결측값 개수를 출력하지 않는다. 이번 데이터는 이보다 많으므로 이런 경우에 비결측값 개수를 표시하기 위해 show_counts 파라미터에 True를 전달하면 모두 출력된다.
모든 피처의 Non-Null 개수가 전체 데이터 수인 2,935,849와 같으므로 모든 피처에 결측값이 없다. 메모리 용량은 134mb 정도 되는데, 메모리 사용량은 작업 속도를 위해 가능한 줄이는 것이 좋다.
이번 데이터는 시계열 데이터로 2013년 1월부터 2015년 10월까지의 판매 내역이 시간순으로 기록되어 있다. 시계열 데이터에서는 시간흐름이 중요하다. 2013년 1월 ~ 2015년 9월은 훈련데이터로, 2015년 10월 판매내역은 검증데이터로 사용해볼 것이다.
앞 장의 안전 운전자 예측에서는 여러 폴드로 나누어 훈련 데이터와 검증 데이터를 지정했는데(OOF예측) 시계열 데이터에서는 과거가 미래가 뒤섞이면 안되기 때문에 이용할 수 없다. 그러므로 훈련 데이터 중 가장 최근인 2015년 10월 판매 내역을 검증데이터로 사용하는 것이다.
두 번째로 상점에 관한 추가 정보가 담긴 shops 데이터를 살펴본다.
shops.head()

상점명과 상점ID 피처가 있다. 상점명은 러시아어로 되어있는데 첫 단어는 상점이 위치한 도시를 나타낸다고 한다. 이를 이용해 추후 shop_name에서 첫 단어를 추출해 도시 피처를 새로 만들 예정이다.
shops 데이터의 shop_id 피처는 위에 첫 번째로 살펴본 sales_train에도 있는 피처다. 그러므로 shop_id를 기준으로 sales_train과 shops를 병합할 수 있다.
shops.info()

shops도 info를 호출해보면 상점은 60개, 결측값은 없고 메모리 사용량도 적다.
세 번째로 items 데이터를 살펴보자.
items.head()

items 데이터는 상품명, 상품ID, 상품분류ID로 구성되어 있다.
상품명 또한 러시아어인데 상품명에서는 유용한 정보를 얻기 힘들어 모델링할 때 제거한다.
item_id 피처는 첫 번째로 본 slaes_train 데이터에도 존재해서 item_id 피처를 기준으로 sales_train과 items를 병합하도록 한다.
items.info()

상품은 총 22170개, 결측값은 없다.
이번에는 item_categories 데이터를 살펴본다.
item_categories.head()
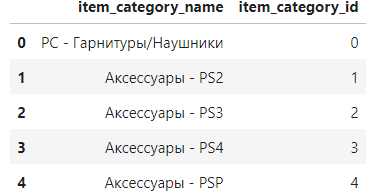
상품분류명, 상품분류 ID로 구성되어 있다.
sales_train에 item_category_id 피처가 있으므로 이 피처를 기준으로 sales_train과 item_categories를 병합한다.
상품 분류명도 러시아어인데 러시아어에 대해 잘 몰라도 번역기나 다른 사람들의 캐글 노트북, 토론을 참고하면 정보를 얻을 수 있다. 실제로 상품 분류명의 첫 단어는 대분류를 뜻한다. 추후 피처 엔지니어링 시에 대분류 피처도 만든다.
item_categories.info()

상품분류는 84개, 결측값은 없다.
테스트 데이터를 살펴보자.
test.head()

테스트 데이터의 식별자인 ID, 상점 ID, 상품 ID로 구성되어 있다. 여기서 각 상점의 상품별 월간 판매량을 예측해야 한다.
데이터 병합
지금까지 데이터가 어떻게 구성되어 있는지 살펴보았다. 앞서 분석한대로 병합하기로 했던 데이터를 병합해보려고 한다. 병합한 데이터를 활용해 피처 요약표를 만들고 시각화 할 수 있다.
sales_train, shops, items, item_categories 데이터를 판다스의 merge()를 사용해 병합한다.
- merge(): 하나 이상의 열을 기준으로 DataFrame 행을 합쳐준다.
기준이 되는 DataFrame에서 merge() 함수를 호출하고, 병합할 DataFrame을 인수로 넣어주면 된다. on 파라미터는 병합 시 기준이 되는 피처를 전달하고, how 파라미터에 'left'를 전달하면 왼쪽 DataFrame의 모든 행을 포함하는 결과를 반환한다.
train = sales_train.merge(shops, on = 'shop_id', how = 'left')
train = train.merge(items, on = 'item_id', how = 'left')
train = train.merge(item_categories, on = 'item_category_id', how = 'left')
train.head()
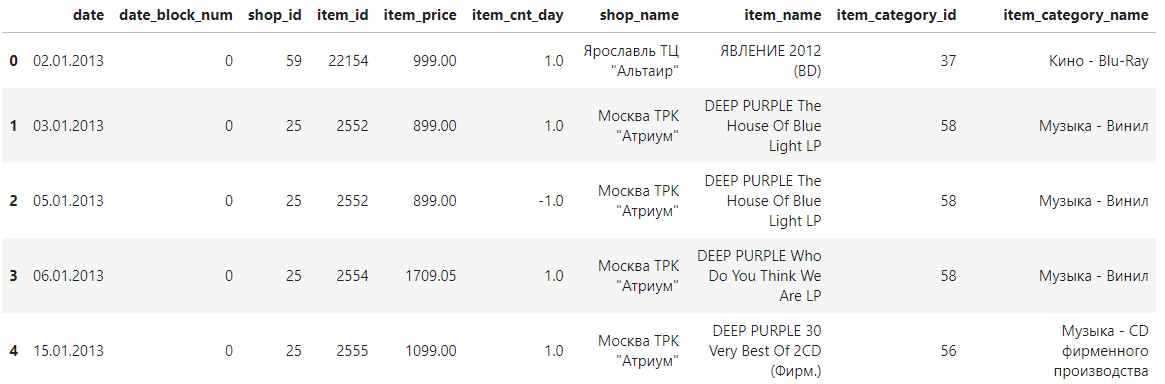
데이터가 잘 병합됐다.
피처 요약표 만들기
병합한 train 데이터를 활용해 피처 요약표를 만들어 보자. 이번 피처 요약표에서는 데이터 타입, 결측값 개수, 고윳값 개수, 첫 번째 값, 두 번째 값을 담아본다.
def resumetable(df):
print(f'데이터셋 형상: {df.shape}')
summary = pd.DataFrame(df.dtypes, columns = ['데이터 타입'])
summary = summary.reset_index()
summary = summary.rename(columns = {'index' : '피처'})
summary['결측값 개수'] = df.isnull().sum().values
summary['고윳값 개수'] = df.nunique().values
summary['첫 번째 값'] = df.loc[0].values
summary['첫 번째 값'] = df.loc[1].values
return summary
resumetable(train)
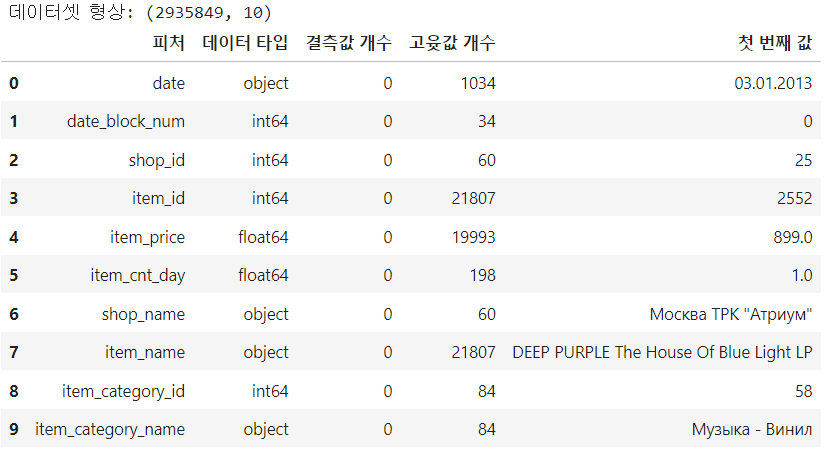
데이터 타입은 object, int64, float64로 다양하고, 앞에서 보았듯이 결측값은 없다.
각 고유값 개수를 살펴보면 shop_id와 shop_name, item_id과 item_name, item_category_id와 item_category_name 피처의 고윳값 개수가 서로 같다. 이는 id와 name이 일대일로 매칭 된다는 뜻이다. 같은 정보를 갖는 두 피처는 id와 name 둘 중 하나만 있어도 되기 때문에 둘 중 하나는 제거한다.
다만 name 피처 중 모델링에 도움이 되는 파생 피처를 만들 수 있는 경우가 있다.
데이터 시각화
위에서 병합한 train 데이터를 이용해 데이터 시각화를 해보자. 이번 장에서는 피처 개수가 많지 않고, 일부는 식별자나 문자 데이터기 때문에 시각화할 게 많이 없다.
일별 판매량
train에서 식별자나 문자 데이터를 제외하면 item_cnt_day 피처와 item_price 피처만 남는다.
수치형 데이터인 이 두 피처를 박스플롯으로 시각화해보겠다.
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
sns.boxplot(y = 'item_cnt_day', data = train);

먼저 item_cnt_day 피처를 박스플롯으로 그려보았다. 이상치가 많아서 박스플롯의 모양이 이상하게 그려졌다.
이상치 범위가 과도하게 넓어서 1~3사분위 수를 나타내는 박스 모양이 납작해져 거의 보이지 않는다. 이렇게 과한 이상치는 제거해야한다. 이상치 제거는 성능개선 절에서 다루게 될 것이다.
얼마 이상을 이상치로 정해야 하는지 정해진 건 없지만 여기서는 item_cnt_day가 1000 이상인 데이터를 제거할 계획이다.
판매가(상품가격)
sns.boxplot(y = 'item_price', data = train);

item_price 피처의 박스플롯도 박스가 납작하다. 이번에도 역시 이상치 때문이다. 300,000루블(약 450만 원)이 넘는 판매가가 있다. 추후 판매가가 50,000루블 이상인 이상치는 제거하도록 한다.
그룹화
데이터를 특정 피처 기준으로 그룹화해서 그려본다. 특정 피처를 기준으로 그룹화해서 원하는 집계값을 구하려면 groupby() 함수를 사용하면 된다.
train의 data_block_num 피처를 기준으로 그룹화해 item_cnt_day 피처 값의 합을 구하는 코드다. 즉, 월별(date_block_num) 월간 판매량(item_cnt_day의 합)을 구하는 것이다.
group = train.groupby('date_block_num').agg({'item_cnt_day': 'sum'})
group.reset_index() # 인덱스 재설정
<groupby 작동 원리>
1. DataFrame에 있는 한 개 이상의 피처를 기준으로 데이터를 분리한다. (위 코드에서는 date_block_num)
2. 분리된 각 그룹에 함수를 적용해 집곗값을 구한다. (agg함수로 다수의 함수를 한번에 적용)
3. 기준 피처별로 집곗값 결과를 하나로 결합한다.
reset_index()를 호출하지 않으면 그룹화한 date_block_num 피처가 인덱스로 설정된다.
그래프를 그릴 때 date_block_num 피처를 사용해야 하므로 reset_index()로 새로운 인덱스를 만들었다.
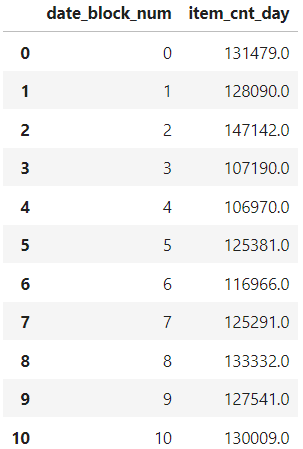
각 date_block_num별로 item_cnt_day 합이 잘 집계되었다.
이제 groupby() 함수로 월별 판매량, 상품분류별 판매량, 상점별 판매량을 막대그래프로 그려볼 것이다.
이 그래프 들로 모델링할 때 도움될 정보는 얻지 못하지만, 상품 판매량 양상을 대략 알아볼 수 있다.
월별 판매량
mpl.rc('font', size = 13)
figure, ax = plt.subplots()
figure.set_size_inches(11, 5)
# 월별 총 상품 판매량
group_month_sum = train.groupby('date_block_num').agg({'item_cnt_day': 'sum'})
group_month_sum = group_month_sum.reset_index()
# 월별 총 상품 판매량 막대그래프
sns.barplot(x = 'date_block_num', y = 'item_cnt_day', data = group_month_sum)
# 그래프 제목, x축 라벨, y축 라벨명 설정
ax.set(title = 'Distribution of monthly item counts by date block number',
xlabel = 'Date block number',
ylabel = 'Monthly item counts');
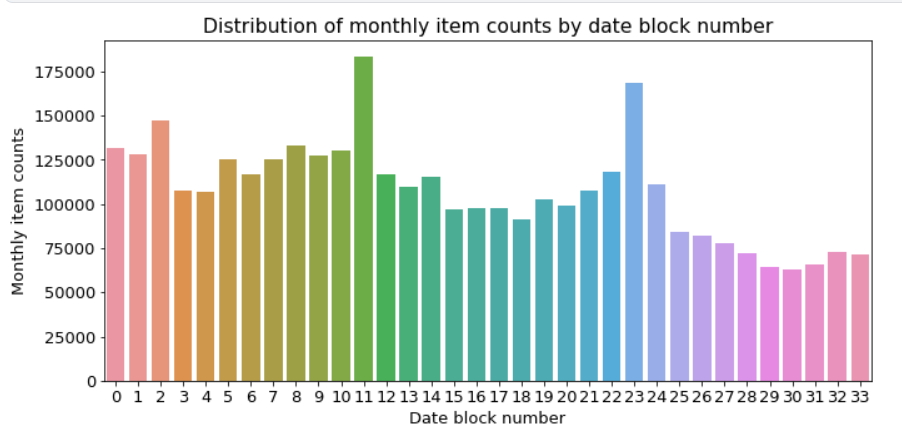
이 그래프로 date_block_num 0부터 33까지, 즉 2013년 1월부터 2015년 10월까지 월별 월간 판매량을 알 수 있다. 11(2013년 12월)과 23(2014년 12월)일 때 판매량이 가장 많다. 연말이라 판매량이 급증한 것으로 볼 수 있다.
상품분류별 판매량
상품분류의 개수는 피처 고윳값 개수를 알려주는 nunique() 함수로 구할 수 있다.
train['item_category_id'].nunique()
상품분류는 총 84개로, 이를 모두 막대 그래프에 표현하기에는 많으니 판매량이 10000개를 초과하는 상품 분류만 추출해서 그려보자.
figure, ax = plt.subplots()
figure.set_size_inches(11, 5)
# 상품분류별 총 상품 판매량
group_cat_sum = train.groupby('item_category_id').agg({'item_cnt_day': 'sum'})
group_cat_sum = group_cat_sum.reset_index()
# 총 판매량이 10,000개를 초과하는 상품분류만 추출
group_cat_sum = group_cat_sum[group_cat_sum['item_cnt_day'] > 10000]
# 상품분류별 총 상품 판매량 막대그래프
sns.barplot(x = 'item_category_id', y='item_cnt_day', data=group_cat_sum)
ax.set(title = 'Distribution of total item counts by item category id',
xlabel = 'Item category ID',
ylabel = 'Total item counts')
ax.tick_params(axis = 'x', labelrotation=90) # x축 라벨 회전
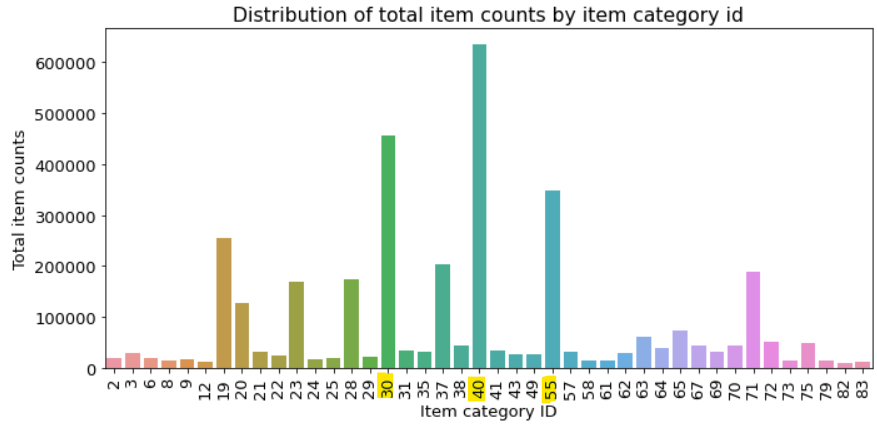
ID 40인 상품분류가 가장 많이 팔렸다. 그 다음은 30과 55다. 몇몇 상품분류가 다른 범주에 비해 많이 팔린다.
상점별 판매량
마지막으로 상점별 월간 판매량을 살펴보자. 상점 개수는 60개로 많기 때문에 판매량이 10000개를 초과하는 상점만 추출하여 막대그래프를 그린다.
figure, ax= plt.subplots()
figure.set_size_inches(11, 5)
# 상점별 총 상품 판매량
group_shop_sum = train.groupby('shop_id').agg({'item_cnt_day': 'sum'})
group_shop_sum = group_shop_sum.reset_index()
group_shop_sum = group_shop_sum[group_shop_sum['item_cnt_day'] > 10000] # 10000개 초과하는 상점
# 상점별 총 상품 판매량 막대그래프
sns.barplot(x = 'shop_id', y='item_cnt_day', data = group_shop_sum)
ax.set(title = 'Distribution of total item counts by shop id',
xlabel = 'Shop ID',
ylabel = 'Total item counts')
ax.tick_params(axis = 'x', labelrotation=90)
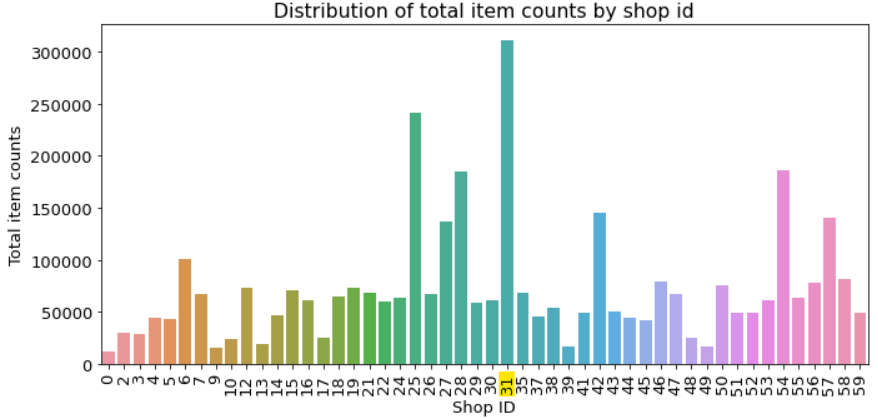
ID가 31인 상점이 가장 많은 상품을 판매했다. 그 다음은 25가 많이 판매했다. 여기서도 몇몇 상점이 다른 상점보다 많이 판매하는 양상을 보인다.
분석 정리
1. 대회의 타깃값 규정 상, 판매량 관련 피처의 값은 모두 0~20으로 제한
2. 시계열 데이터이므로 순서를 꼭 지켜야함. (검증 데이터는 훈련 데이터 중 가장 최근 1개월치 이용)
3. 타깃값은 월별 판매량을 예측해야 하나, 주어진 데이터에는 일별 판매량만 있으므로 같은 달의 일별 판매량을 합쳐 타깃값을 구한다.
4. 추가 정보 파일(상점, 상품, 상품분류)는 각각의 ID(상점 ID, 상품 ID, 상품분류 ID)를 기준으로 훈련 데이터에 병합할 수 있다.
5. 속도를 위해 메모리 관리가 필요함
6. 파생 피처 추가: 상점 명과 상품분류명 첫 단어는 각각 도시와 대분류를 의미
7. 월별 판매량만 구하면 되므로 date 피처는 제거
8. 상점 ID, 상품 ID, 상품분류 ID는 각각 상점명, 상품명, 상품분류명과 일대일 매칭되므로 id와 name 둘 중 하나는 제거한다.
9. 박스플롯을 그렸을 때 일별 판매량과 판매가에 이상치가 보였으므로 이상치를 제거한다
10. 모든 데이터에 결측값이 없다
참고 교재

머신러닝·딥러닝 문제해결 전략 | 신백균
[머신러닝·딥러닝 문제해결 전략 - chapter9]
'ML,DL' 카테고리의 다른 글
| [머신러닝/딥러닝] 병든 잎사귀 식별 경진대회: 베이스라인 모델 및 성능개선 (0) | 2023.02.05 |
|---|---|
| [머신러닝/딥러닝] 병든 잎사귀 식별 경진대회: 분석정리 및 시각화 (0) | 2023.02.04 |
| [머신러닝/딥러닝] 안전 운전자 예측 경진대회: 분석정리 및 시각화 (0) | 2022.11.07 |
| [머신러닝/딥러닝] 범주형 데이터 이진분류 경진대회: 분석정리 및 시각화 (1) | 2022.10.04 |
| [머신러닝/딥러닝] 피처 스케일링: min-max 정규화, 표준화 (2) | 2022.09.19 |



